
Get started with Charmed Kubeflow
Imagine your organisation required a full MLOps platform where data scientists, ML engineers and MLOps engineers could collaborate in advancing the cutting edge of ML solutions. A popular platform that meets this need is Kubeflow. But deploying and maintaining a production-grade Kubeflow is a huge task, requiring lots of manual configuration. And deploying it into your own unique environment might lead you to issues that nobody has seen before- issues you’ll have to solve yourself.
Enter the hero of our story: Charmed Kubeflow. Charmed Kubeflow is a charm bundle that gives you a simple, out of the box way to deploy Kubeflow with a single command. It sets sensible configuration defaults, while still permitting you the flexibility to configure as you like - the best of both worlds. It also equips your deployment with all the superpowers of Juju.
Right, let’s get our hands dirty. In the remainder of this tutorial, we’re going to actually deploy Charmed Kubeflow for ourselves! Don’t worry, using Juju, we’ll get this deployment done with minimal effort.
Requirements:
This tutorial assumes you will be deploying Kubeflow on a public cloud VM with the following specs:
- Runs Ubuntu 20.04 (focal) or later.
- Has at least 4 cores, 32GB RAM and 50GB of disk space available.
- Is connected to the internet for downloading the required snaps and charms.
- Has
python3installed.
We’ll also assume that you have a laptop that meets the following conditions:
- Has an SSH tunnel open to the VM with port forwarding and a SOCKS proxy. To see how to set this up, see How to setup SSH VM Access.
- Runs Ubuntu 20.04 (focal) or later.
- Has a web browser installed e.g. Chrome / Firefox / Edge.
In the remainder of this tutorial, unless otherwise stated, it is assumed you will be running all command line operations on the VM, through the open SSH tunnel. It’s also assumed you’ll be using the web browser on your local machine to access the Kubeflow dashboard.
Contents:
- Install and prepare MicroK8s
- Install Juju
- Deploy Charmed Kubeflow
- Configure Dashboard Access
- Verify Kubeflow Deployment
- Troubleshooting
- Get in Touch
Install and prepare MicroK8s
Let’s begin our journey. Every Kubeflow instance needs a K8s cluster to run on. To keep things simple, we’ll be running our Kubeflow instance on MicroK8s, which is the easiest and fastest way to spin up a K8s cluster.
MicroK8s is installed from a snap package. We’ll be installing the snap with classic confinement. See if you can figure it out yourself! Install the package microk8s from the channel 1.26/stable.
Solution: Install MicroK8s
sudo snap install microk8s --classic --channel=1.26/stable
More info: Install MicroK8s
- The exact channel we used for this tutorial is not important. It’s just the one we’ve tested. The published snap maintains different
channelsfor different releases of Kubernetes. - Newer versions of MicroK8s can be installed with strict confinement. But the version we used to test this tutorial can only be installed with classic confinement. Feel free to experiment with a newer version, if you’re feeling adventurous, and let us know how you get on.
Great! microk8s has now been installed, and will automatically start running in the background. Now it’s time to configure it, to get it ready for Kubeflow.
Next, a little trick. To avoid having to use sudo for every MicroK8s command, run these commands:
sudo usermod -a -G microk8s $USER
newgrp microk8s
Note: You’ll need to re-run
newgrp microk8sany time you open a new shell session.
Now, although we’ll be using juju as our main configuration tool to work with our Kubeflow deployment, sometimes we’ll need to interact with MicroK8s directly through the kubectl command. For this to work, we need to grant ownership of any kubectl configuration files to the user running kubectl. Run this command to do that:
sudo chown -f -R $USER ~/.kube
Great! That does it for setting permissions. Next stop: add-ons!
MicroK8s is a completely functional Kubernetes, running with the least amount of overhead possible. However, for our purposes we will need a Kubernetes with a few more features. A lot of extra services are available as MicroK8s addons - code which is shipped with the snap and can be turned on and off when it is needed. Let’s enable some of these features to get a Kubernetes where we can usefully install Kubeflow. We will add a DNS service, so the applications can find each other; storage; an ingress controller so we can access Kubeflow components; and the MetalLB load balancer application.
See if you can figure it out yourself! Enable the following Microk8s add-ons to configure your Kubernetes cluster with extra services needed to run Charmed Kubeflow: dns, hostpath-storage, ingress and metallb for the IP address range 10.64.140.43-10.64.140.49.
Solution: Enable MicroK8s addons
microk8s enable dns hostpath-storage ingress metallb:10.64.140.43-10.64.140.49 rbac
Great job! You’ve now installed and configured MicroK8s.
Now, it can take 5 minutes or so before all the addons we configured are ready for action. Unfortunately, there is no straightforward way to verify that the addons are ready. This is a known gap in MicroK8s - if you’d like to change this, please say so on this GitHub issue. But for the moment, our best bet is to just wait 5 minutes before doing anything else. In the meantime, go stretch your legs!
Although there’s no way to guarantee all the addons are available, a basic sanity check we can do is to ask MicroK8s for a status output. Run the following command:
microk8s status
In the output, MicroK8s should be reported as running, and all addons that we enabled earlier should be listed as enabled:: dns, storage, ingress and metallb. If this is not the case, wait a little while longer and run the command again.
Sample Output (yours may differ slightly)
microk8s is running
high-availability: no
datastore master nodes: 127.0.0.1:19001
datastore standby nodes: none
addons:
enabled:
dns # (core) CoreDNS
ha-cluster # (core) Configure high availability on the current node
hostpath-storage # (core) Storage class; allocates storage from host directory
ingress # (core) Ingress controller for external access
metallb # (core) Loadbalancer for your Kubernetes cluster
storage # (core) Alias to hostpath-storage add-on, deprecated
disabled:
community # (core) The community addons repository
dashboard # (core) The Kubernetes dashboard
gpu # (core) Automatic enablement of Nvidia CUDA
helm # (core) Helm 2 - the package manager for Kubernetes
helm3 # (core) Helm 3 - Kubernetes package manager
host-access # (core) Allow Pods connecting to Host services smoothly
mayastor # (core) OpenEBS MayaStor
metrics-server # (core) K8s Metrics Server for API access to service metrics
prometheus # (core) Prometheus operator for monitoring and logging
rbac # (core) Role-Based Access Control for authorisation
registry # (core) Private image registry exposed on localhost:32000
Great, you have now installed and configured MicroK8s, and it’s running and ready! We now have a K8s cluster where we can deploy our Kubeflow instance.
Install Juju
Juju is an operation Lifecycle manager (OLM) for clouds, bare metal or Kubernetes. We will be using it to deploy and manage the components which make up Kubeflow.To install Juju from snap, run this command:
sudo snap install juju --classic --channel=3.1/stable
More info: Install MicroK8s
- The exact channel we used for this tutorial is not important. It’s just the one we’ve tested. The published snap maintains different
channelsfor different releases of Kubernetes. - The version of Juju we used to test this tutorial can only be installed with classic confinement.
On some machines there might be a missing folder which is required for juju to run correctly. Because of this please make sure to create this folder with:
mkdir -p ~/.local/share
As a next step we can configure microk8s to work properly with juju by running:
microk8s config | juju add-k8s my-k8s --client
Command microk8s config retrieves the client’s kubernetes config which is then registered to juju kubernetes endpoints.
Now, run the following command to deploy a Juju controller to the Kubernetes we set up with MicroK8s:
juju bootstrap my-k8s uk8sx
Sit tight while the command completes! The controller may take a minute or two to deploy.
The controller is Juju’s agent, running on Kubernetes, which can be used to deploy and control the components of Kubeflow.
Next, we’ll need to add a model for Kubeflow to the controller. Run the following command to add a model called kubeflow:
juju add-model kubeflow
The controller can work with different models, which map 1:1 to namespaces in Kubernetes. In this case, the model name must be kubeflow, due to an assumption made in the upstream Kubeflow Dashboard code.
Great job: Juju has now been installed and configured for Kubeflow!
Deploy Charmed Kubeflow
Before deploying, run these commands:
sudo sysctl fs.inotify.max_user_instances=1280
sudo sysctl fs.inotify.max_user_watches=655360
We need to run the above because under the hood, microk8s uses inotify to interact with the filesystem, and in kubeflow sometimes the default inotify limits are exceeded. Update /etc/sysctl.conf with the following lines if you want these commands to persist across machine restarts:
fs.inotify.max_user_instances=1280
fs.inotify.max_user_watches=655360
Finally, we’re ready to deploy Charmed Kubeflow! Go ahead and run this code to deploy the Charmed Kubeflow bundle with Juju:
juju deploy kubeflow --trust --channel=1.8/stable
Be patient. This deployment process can take 5-10 minutes.
In the meantime, what’s going on here? Take a look at your output.
Sample Output (yours may differ slightly)
juju deploy kubeflow --trust --channel=1.8/stable
Located bundle "kubeflow" in charm-hub, revision 414
Located charm "admission-webhook" in charm-hub, channel 1.8/stable
Located charm "argo-controller" in charm-hub, channel 3.3.10/stable
Located charm "dex-auth" in charm-hub, channel 2.36/stable
Located charm "envoy" in charm-hub, channel 2.0/stable
Located charm "istio-gateway" in charm-hub, channel 1.17/stable
Located charm "istio-pilot" in charm-hub, channel 1.17/stable
Located charm "jupyter-controller" in charm-hub, channel 1.8/stable
Located charm "jupyter-ui" in charm-hub, channel 1.8/stable
Located charm "katib-controller" in charm-hub, channel 0.16/stable
Located charm "mysql-k8s" in charm-hub, channel 8.0/stable
Located charm "katib-db-manager" in charm-hub, channel 0.16/stable
Located charm "katib-ui" in charm-hub, channel 0.16/stable
Located charm "kfp-api" in charm-hub, channel 2.0/stable
Located charm "mysql-k8s" in charm-hub, channel 8.0/stable
Located charm "kfp-metadata-writer" in charm-hub, channel 2.0/stable
Located charm "kfp-persistence" in charm-hub, channel 2.0/stable
Located charm "kfp-profile-controller" in charm-hub, channel 2.0/stable
Located charm "kfp-schedwf" in charm-hub, channel 2.0/stable
Located charm "kfp-ui" in charm-hub, channel 2.0/stable
Located charm "kfp-viewer" in charm-hub, channel 2.0/stable
Located charm "kfp-viz" in charm-hub, channel 2.0/stable
Located charm "knative-eventing" in charm-hub, channel 1.10/stable
Located charm "knative-operator" in charm-hub, channel 1.10/stable
Located charm "knative-serving" in charm-hub, channel 1.10/stable
Located charm "kserve-controller" in charm-hub, channel 0.11/stable
Located charm "kubeflow-dashboard" in charm-hub, channel 1.8/stable
Located charm "kubeflow-profiles" in charm-hub, channel 1.8/stable
Located charm "kubeflow-roles" in charm-hub, channel 1.8/stable
Located charm "kubeflow-volumes" in charm-hub, channel 1.8/stable
Located charm "metacontroller-operator" in charm-hub, channel 3.0/stable
Located charm "minio" in charm-hub, channel ckf-1.8/stable
Located charm "mlmd" in charm-hub, channel 1.14/stable
Located charm "oidc-gatekeeper" in charm-hub, channel ckf-1.8/stable
Located charm "pvcviewer-operator" in charm-hub, channel 1.8/stable
Located charm "seldon-core" in charm-hub, channel 1.17/stable
Located charm "tensorboard-controller" in charm-hub, channel 1.8/stable
Located charm "tensorboards-web-app" in charm-hub, channel 1.8/stable
Located charm "training-operator" in charm-hub, channel 1.7/stable
Executing changes:
- upload charm admission-webhook from charm-hub from channel 1.8/stable with architecture=amd64
- deploy application admission-webhook from charm-hub with 1 unit with 1.8/stable
added resource oci-image
- upload charm argo-controller from charm-hub from channel 3.3.10/stable with architecture=amd64
- deploy application argo-controller from charm-hub with 1 unit with 3.3.10/stable
added resource oci-image
- upload charm dex-auth from charm-hub from channel 2.36/stable with architecture=amd64
- deploy application dex-auth from charm-hub with 1 unit with 2.36/stable
added resource oci-image
- upload charm envoy from charm-hub from channel 2.0/stable with architecture=amd64
- deploy application envoy from charm-hub with 1 unit with 2.0/stable
added resource oci-image
- upload charm istio-gateway from charm-hub from channel 1.17/stable with architecture=amd64
- deploy application istio-ingressgateway from charm-hub with 1 unit with 1.17/stable using istio-gateway
- upload charm istio-pilot from charm-hub from channel 1.17/stable with architecture=amd64
- deploy application istio-pilot from charm-hub with 1 unit with 1.17/stable
- upload charm jupyter-controller from charm-hub from channel 1.8/stable with architecture=amd64
- deploy application jupyter-controller from charm-hub with 1 unit with 1.8/stable
added resource oci-image
- upload charm jupyter-ui from charm-hub from channel 1.8/stable with architecture=amd64
- deploy application jupyter-ui from charm-hub with 1 unit with 1.8/stable
added resource oci-image
- upload charm katib-controller from charm-hub from channel 0.16/stable with architecture=amd64
- deploy application katib-controller from charm-hub with 1 unit with 0.16/stable
added resource oci-image
- upload charm mysql-k8s from charm-hub from channel 8.0/stable with architecture=amd64
- deploy application katib-db from charm-hub with 1 unit with 8.0/stable using mysql-k8s
added resource mysql-image
- upload charm katib-db-manager from charm-hub from channel 0.16/stable with architecture=amd64
- deploy application katib-db-manager from charm-hub with 1 unit with 0.16/stable
added resource oci-image
- upload charm katib-ui from charm-hub from channel 0.16/stable with architecture=amd64
- deploy application katib-ui from charm-hub with 1 unit with 0.16/stable
added resource oci-image
- upload charm kfp-api from charm-hub from channel 2.0/stable with architecture=amd64
- deploy application kfp-api from charm-hub with 1 unit with 2.0/stable
added resource oci-image
- deploy application kfp-db from charm-hub with 1 unit with 8.0/stable using mysql-k8s
added resource mysql-image
- upload charm kfp-metadata-writer from charm-hub from channel 2.0/stable with architecture=amd64
- deploy application kfp-metadata-writer from charm-hub with 1 unit with 2.0/stable
added resource oci-image
- upload charm kfp-persistence from charm-hub from channel 2.0/stable with architecture=amd64
- deploy application kfp-persistence from charm-hub with 1 unit with 2.0/stable
added resource oci-image
- upload charm kfp-profile-controller from charm-hub from channel 2.0/stable with architecture=amd64
- deploy application kfp-profile-controller from charm-hub with 1 unit with 2.0/stable
added resource oci-image
- upload charm kfp-schedwf from charm-hub from channel 2.0/stable with architecture=amd64
- deploy application kfp-schedwf from charm-hub with 1 unit with 2.0/stable
added resource oci-image
- upload charm kfp-ui from charm-hub from channel 2.0/stable with architecture=amd64
- deploy application kfp-ui from charm-hub with 1 unit with 2.0/stable
added resource ml-pipeline-ui
- upload charm kfp-viewer from charm-hub from channel 2.0/stable with architecture=amd64
- deploy application kfp-viewer from charm-hub with 1 unit with 2.0/stable
added resource kfp-viewer-image
- upload charm kfp-viz from charm-hub from channel 2.0/stable with architecture=amd64
- deploy application kfp-viz from charm-hub with 1 unit with 2.0/stable
added resource oci-image
- upload charm knative-eventing from charm-hub from channel 1.10/stable with architecture=amd64
- deploy application knative-eventing from charm-hub with 1 unit with 1.10/stable
- upload charm knative-operator from charm-hub from channel 1.10/stable with architecture=amd64
- deploy application knative-operator from charm-hub with 1 unit with 1.10/stable
added resource knative-operator-image
added resource knative-operator-webhook-image
- upload charm knative-serving from charm-hub from channel 1.10/stable with architecture=amd64
- deploy application knative-serving from charm-hub with 1 unit with 1.10/stable
- upload charm kserve-controller from charm-hub from channel 0.11/stable with architecture=amd64
- deploy application kserve-controller from charm-hub with 1 unit with 0.11/stable
added resource kserve-controller-image
added resource kube-rbac-proxy-image
- upload charm kubeflow-dashboard from charm-hub from channel 1.8/stable with architecture=amd64
- deploy application kubeflow-dashboard from charm-hub with 1 unit with 1.8/stable
added resource oci-image
- upload charm kubeflow-profiles from charm-hub from channel 1.8/stable with architecture=amd64
- deploy application kubeflow-profiles from charm-hub with 1 unit with 1.8/stable
added resource kfam-image
added resource profile-image
- upload charm kubeflow-roles from charm-hub from channel 1.8/stable with architecture=amd64
- deploy application kubeflow-roles from charm-hub with 1 unit with 1.8/stable
- upload charm kubeflow-volumes from charm-hub from channel 1.8/stable with architecture=amd64
- deploy application kubeflow-volumes from charm-hub with 1 unit with 1.8/stable
added resource oci-image
- upload charm metacontroller-operator from charm-hub from channel 3.0/stable with architecture=amd64
- deploy application metacontroller-operator from charm-hub with 1 unit with 3.0/stable
- upload charm minio from charm-hub from channel ckf-1.8/stable with architecture=amd64
- deploy application minio from charm-hub with 1 unit with ckf-1.8/stable
added resource oci-image
- upload charm mlmd from charm-hub from channel 1.14/stable with architecture=amd64
- deploy application mlmd from charm-hub with 1 unit with 1.14/stable
added resource oci-image
- upload charm oidc-gatekeeper from charm-hub from channel ckf-1.8/stable with architecture=amd64
- deploy application oidc-gatekeeper from charm-hub with 1 unit with ckf-1.8/stable
added resource oci-image
- upload charm pvcviewer-operator from charm-hub for series focal from channel 1.8/stable with architecture=amd64
- deploy application pvcviewer-operator from charm-hub with 1 unit on focal with 1.8/stable
added resource oci-image
added resource oci-image-proxy
- upload charm seldon-core from charm-hub from channel 1.17/stable with architecture=amd64
- deploy application seldon-controller-manager from charm-hub with 1 unit with 1.17/stable using seldon-core
added resource oci-image
- upload charm tensorboard-controller from charm-hub from channel 1.8/stable with architecture=amd64
- deploy application tensorboard-controller from charm-hub with 1 unit with 1.8/stable
added resource tensorboard-controller-image
- upload charm tensorboards-web-app from charm-hub from channel 1.8/stable with architecture=amd64
- deploy application tensorboards-web-app from charm-hub with 1 unit with 1.8/stable
added resource tensorboards-web-app-image
- upload charm training-operator from charm-hub from channel 1.7/stable with architecture=amd64
- deploy application training-operator from charm-hub with 1 unit with 1.7/stable
added resource training-operator-image
- add relation argo-controller - minio
- add relation dex-auth:oidc-client - oidc-gatekeeper:oidc-client
- add relation istio-pilot:ingress - dex-auth:ingress
- add relation istio-pilot:ingress - envoy:ingress
- add relation istio-pilot:ingress - jupyter-ui:ingress
- add relation istio-pilot:ingress - katib-ui:ingress
- add relation istio-pilot:ingress - kfp-ui:ingress
- add relation istio-pilot:ingress - kubeflow-dashboard:ingress
- add relation istio-pilot:ingress - kubeflow-volumes:ingress
- add relation istio-pilot:ingress - oidc-gatekeeper:ingress
- add relation istio-pilot:ingress-auth - oidc-gatekeeper:ingress-auth
- add relation istio-pilot:istio-pilot - istio-ingressgateway:istio-pilot
- add relation istio-pilot:ingress - tensorboards-web-app:ingress
- add relation istio-pilot:gateway-info - tensorboard-controller:gateway-info
- add relation katib-db-manager:relational-db - katib-db:database
- add relation kfp-api:relational-db - kfp-db:database
- add relation kfp-api:kfp-api - kfp-persistence:kfp-api
- add relation kfp-api:kfp-api - kfp-ui:kfp-api
- add relation kfp-api:kfp-viz - kfp-viz:kfp-viz
- add relation kfp-api:object-storage - minio:object-storage
- add relation kfp-profile-controller:object-storage - minio:object-storage
- add relation kfp-ui:object-storage - minio:object-storage
- add relation kserve-controller:ingress-gateway - istio-pilot:gateway-info
- add relation kserve-controller:local-gateway - knative-serving:local-gateway
- add relation kubeflow-profiles - kubeflow-dashboard
- add relation kubeflow-dashboard:links - jupyter-ui:dashboard-links
- add relation kubeflow-dashboard:links - katib-ui:dashboard-links
- add relation kubeflow-dashboard:links - kfp-ui:dashboard-links
- add relation kubeflow-dashboard:links - kubeflow-volumes:dashboard-links
- add relation kubeflow-dashboard:links - tensorboards-web-app:dashboard-links
- add relation mlmd:grpc - envoy:grpc
- add relation mlmd:grpc - kfp-metadata-writer:grpc
Deploy of bundle completed.
Wow, that’s a lot of stuff going on! Here you can see the power of using a Juju bundle to deploy kubeflow. From the output you can see the bundle locates, deploys and configures all the necessary charms for us. Without the bundle, we would have had to deploy and configure all of those charms independently ourselves: ouch! There’s a time and a place for doing that, but don’t worry about that for now.
When the deploy command completes, you’ll get a message such as:
Deploy of bundle completed.
This means that all the components of the bundle have been kickstarted into action. However, this doesn’t mean Kubeflow is ready yet. After deployment, the various components of the bundle need some time to initialise and establish communication with each other. Be patient - usually this will take somewhere between 15 minutes and 1 hour.
So, how do you know when the whole bundle is ready, then? You can do this using the juju status command. First, let’s run a basic status command and review the output. Run the following command to print out the status of all the components of Juju:
juju status
Review the output for yourself. You should see some summary information, a list of Apps and associated information, and another list of Units and their associated information. Don’t worry too much about what this all means for now. If you’re interested in learning more about this command and its output, see the Juju Status command.
The main thing we’re interested in at this stage is the statuses of all the applications and units in our bundle. We want all the statuses to eventually become active, indicating that the bundle is ready. Run the following command to keep a watch on the components which are not active yet:
juju status --watch 5s
This will periodically run a juju status command. When all of the components on the screen are in “Active” status, then we know that our bundle is ready.
Don’t be surprised if some of the components’ statuses change to blocked or error every now and then. This is expected behavior, and these statuses should resolve by themselves as the bundle configures itself. However, if components remain stuck in the same error states, consult the troubleshooting steps below.
While you’re waiting for the Kubeflow bundle to prepare itself, feel free to skip ahead to the next section of this tutorial, which steps you through some post-install configuration tasks.
Configure Dashboard Access
It’s all well and good to run Kubeflow, but how are we going to interact with it as a user? That’s where the dashboard comes in. We’ll get to that later, but right now let’s configure some components so that we can access the dashboard.
First off, run this command to check the IP address of the Istio ingress gateway load balancer, which is the entry point for our entire bundle:
microk8s kubectl -n kubeflow get svc istio-ingressgateway-workload -o jsonpath='{.status.loadBalancer.ingress[0].ip}'
You should see an output of 10.64.140.43, which is the IP address of this component in the default microk8s configuration. If some see something else, don’t worry - just replace 10.64.140.43 with whatever IP address you see in the remainder of this tutorial’s instructions.
In order to access kubeflow through its dashboard service, we’ll need to configure the bundle a bit so that it supports authentication and authorization. To do so, run these commands:
juju config dex-auth public-url=http://10.64.140.43.nip.io
juju config oidc-gatekeeper public-url=http://10.64.140.43.nip.io
This tells the authentication and authorization components of the bundle that users who access the bundle will be doing so via the URL http://10.64.140.43.nip.io. In turn, this allows those components to construct appropriate responses to incoming traffic.
To enable simple authentication, and set a username and password for your Kubeflow deployment, run the following commands:
juju config dex-auth static-username=admin
juju config dex-auth static-password=admin
Feel free to use a different (more secure!) password if you wish.
Great! Our bundle has now been configured to allow access to the dashboard through a browser.
Verify Charmed Kubeflow Deployment
Great! We’ve deployed and configured Kubeflow. But how do we know that we did everything right? One quick thing we can do is try to log in. Let’s go!
Open a browser and visit the following URL:
http://10.64.140.43.nip.io
You should then see the dex login screen. Enter the username (it does say email address, but whatever string you entered to configure it will work fine) and your password from the previous configuration step.
You should now see the Kubeflow “Welcome” page:

Click on the “Start Setup” button. On the next screen you will be asked to create a namespace. This is just a way of keeping all the files and settings from one project in a single, easy-to-access place. Choose any name you like:

Once you click on the “Finish” button, the Dashboard will be displayed!
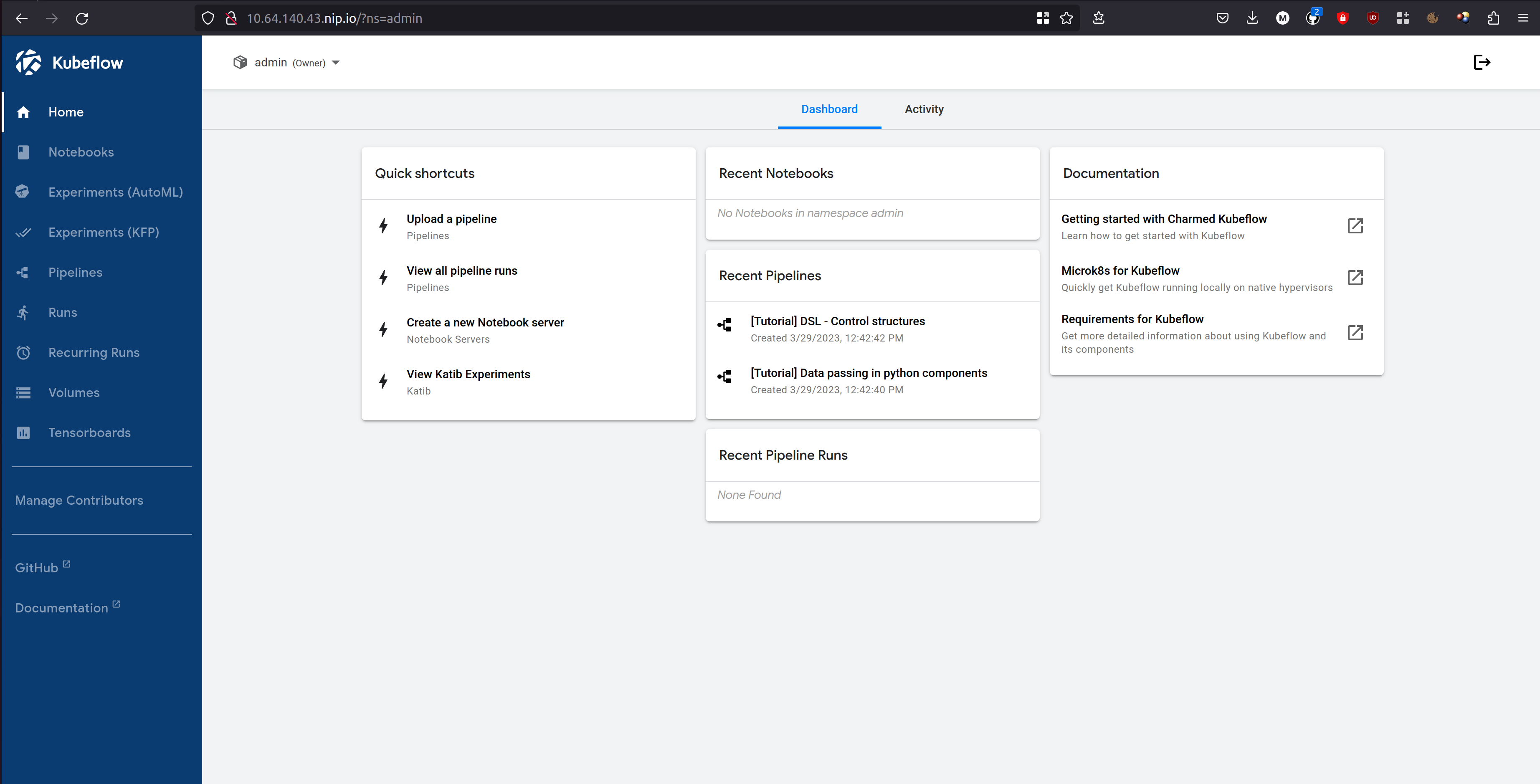
More information on accessing the dashboard can be found in this guide.
Phew, we’ve deployed Kubeflow! Now it’s time to do some cool things with it.
Troubleshooting
Oidc-gatekeeper “Waiting for pod startup to complete”
If you see youroidc-gatekeeper/0 unit in juju status output in waiting state with
oidc-gatekeeper/0* waiting idle 10.1.121.241 Waiting for pod startup to complete.
You can reconfigure the public-url configuration for the charm with following commands
juju config oidc-gatekeeper public-url=""
juju config oidc-gatekeeper public-url=http://10.64.140.43.nip.io
This should set the oidc-gatekeeper unit into the active state. You can track the progress in this GitHub issue.
Crash Loop Backoff
If you see crash loop backoff in your juju status output it might mean that you forgot to update inotify as follows:
sudo sysctl fs.inotify.max_user_instances=1280
sudo sysctl fs.inotify.max_user_watches=655360
After doing that, the applications will slowly turn to active.
crash loop backoff sample output
> App Version Status Scale Charm Channel Rev Address Exposed Message
> kfp-api res:oci-image@e08e41d waiting 1 kfp-api 2.0/stable 298 10.152.183.106 no
> kfp-persistence res:oci-image@516e6b8 waiting 1 kfp-persistence 2.0/stable 294 no
> Unit Workload Agent Address Ports Message
> kfp-api/0* error idle 10.1.216.122 8888/TCP,8887/TCP crash loop backoff: back-off 5m0s restarting failed container=ml-pipeline-api-server pod=kfp-api-6658f6984b-dd8mp_kub...
> kfp-persistence/0* error idle 10.1.216.123
To see if this is the issue, manually check the state of the pods in the cluster by running
microk8s kubectl get po -n kubeflow
Pods are expected to be in a Running state. If some pods are in CrashLoopBackOff you can further inspect the pod by checking the logs with:
microk8s kubectl logs -n kubeflow <name-of-the-pod>
If you see error messages like this one: “error”:“too many open files” then it’s likely inotify was the issue. This behavior has been previously observed on pods of katib-controller, kubeflow-profiles, kfp-api and kfp-persistence.
Get in Touch
Did you find this tutorial helpful? Painful? Both? We’d love to hear from you. Get in touch with us on Matrix.
Last updated 2 months ago.