
See also: How to build an MLOps pipeline with MLFlow, Seldon Core and Kubeflow
See more: List of MLOps tools
An MLOps pipeline is a set of steps that automates the process of creating and maintaining AI/ML models. In other words, Data Scientists create multiple notebooks while building their experiments, and naturally the next step is a transition from experiments to production-ready code. The best way to do this is to build an effective MLOps pipeline.
The MLOps process is basically divided into two main phases – experimentation and realisation. During experiments, data scientists focus on generating lots of ideas and validating them. On the other hand in the second realisation phase, we select a subset of the most promising ideas and deliver them to production. And for sure, only when they are a part of the business operations can they deliver the expected value.
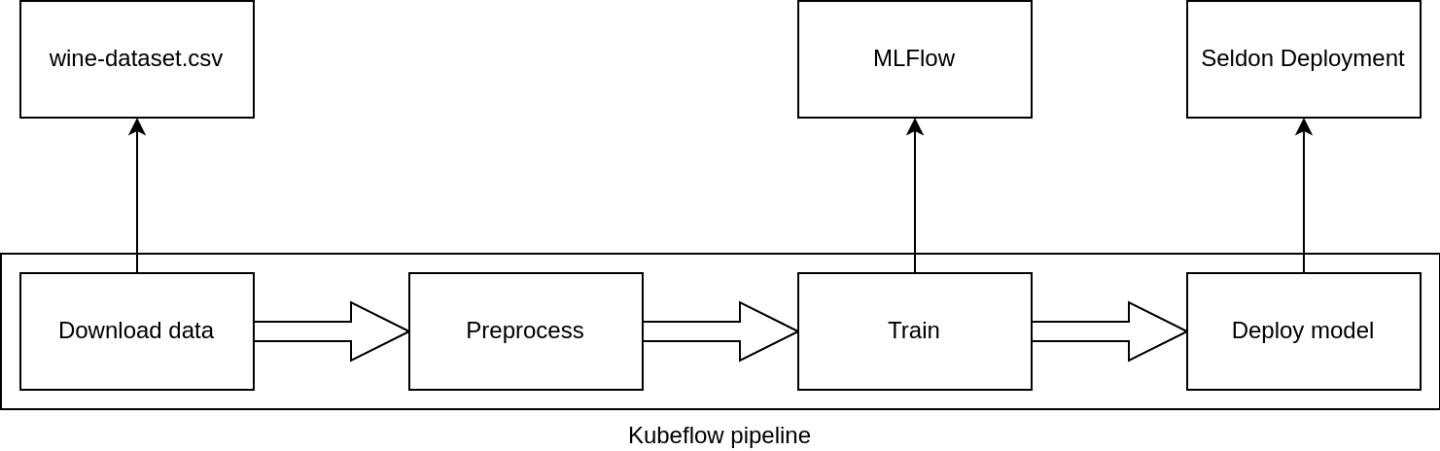
An MLOps pipeline consists of the following four steps:
- Download the data
- Preprocess the data
- Train the model
- Deploy the model
Last updated 1 year, 7 months ago.